Razões para deep reinforcement learning não funcionar
Essa é uma compilação de textos que eu encontrei na internet em momentos de frustração com meu trabalho. Eu os resumi e traduzi para compartilhar com as pessoas sempre que me perguntarem porque trabalhar com DRL é uma desgraça.
- Comentários do Karpathy
- Texto: Lessons Learned Reproducing a Deep Reinforcement Learning Paper
- Texto: Deep Reinforcement Learning Doesn’t Work Yet
Comentários do Karpathy
O trecho abaixo é um comentário do Andrej Karpathy, da Tesla, neste link.
If it makes you feel any better, I’ve been doing this for a while and it took me last ~6 weeks to get a from-scratch policy gradients implementation to work 50% of the time on a bunch of RL problems. And I also have a GPU cluster available to me, and a number of friends I get lunch with every day who’ve been in the area for the last few years. Also, what we know about good CNN design from supervised learning land doesn’t seem to apply to reinforcement learning land, because you’re mostly bottlenecked by credit assignment / supervision bitrate, not by a lack of a powerful representation. Your ResNets, batchnorms, or very deep networks have no power here. SL wants to work. Even if you screw something up you’ll usually get something non-random back. RL must be forced to work. If you screw something up or don’t tune something well enough you’re exceedingly likely to get a policy that is even worse than random. And even if it’s all well tuned you’ll get a bad policy 30% of the time, just because. Long story short your failure is more due to the difficulty of deep RL, and much less due to the difficulty of “designing neural networks”.
Texto: Lessons Learned Reproducing a Deep Reinforcement Learning Paper
Fonte: http://amid.fish/reproducing-deep-rl
-
Ao trabalhar com métodos programados no computador, nós frequentemente nos deparamos com problemas cuja solução não é óbvia. Quando o método não necessita de treinamento, é mais rápido e fácil ter várias ideias do que pode solucionar um problema e testar tudo em segundos do que realmente pensar na origem do problema. No caso de um algoritmo de RL, cada novo teste leva um ou mais dias, então é necessário pensar no problema para selecionar a solução mais provável, ou encontrar uma solução melhor, mesmo que não seja óbvia.
-
Ao reproduzir o artigo de outra pessoa:
- O que você aprende: como fazer um método de DRL funcionar, melhorando nossas habilidades de RL engineers.
- O que você pensa que vai aprender, mas não aprende: a surgir com novas ideias relevantes de pesquisa. Isso é melhor feito através da leitura crítica de outros artigos e do conhecimento de vários termos-chave da área.
-
Algumas dicas que o autor tentou martelar nos leitores:
- se você vai usar um método de RL, tente não implementá-lo, LOL
- tente medir tudo o que é possível durante o treinamento. Não só métricas como recompensa ou erro da rede, mas outras métricas indiretas de sucesso
- escrever um diário dos experimentos para se lembrar do que você já tentou
-
Outro ponto interessante do relato. O autor pensou que iria levar 3 meses pra terminar a reprodução do paper, mas levou 8 meses. A maior parte do tempo é desprendida fazendo o algoritmo funcionar num exemplo simples. Depois, a demora está em instrumentar testes. Seguem abaixo os tempos que o autor demorou para:
- implementar a primeira versão do método (30 horas)
- fazer ele funcionar num exemplo básico (110 horas)
- fazer ele funcionar num exemplo novo (10 horas) e finalmente
- conseguir rodar testes consistentes (60 horas).
Texto: Deep Reinforcement Learning Doesn’t Work Yet
Fonte: https://www.alexirpan.com/2018/02/14/rl-hard.html
Esse artigo lista diversos motivos pra métodos de DRL não funcionarem.
- ineficiência de amostras: necessários milhões de exemplos pro método aprender
- nunca é o método mais eficiente: métodos especializados pra cada problema quase sempre têm resultados melhores do que DRL: e.g., algoritmos de controle para robôs humanoides
- criação da função de recompensa: precisa ser feita por uma pessoa e é difícil criar uma função que guia o agente de maneira óbvia para o objetivo, sem ser esparsa (+1 por vencer)
- retorno esperado pode ter máximos locais: mesmo que o código esteja correto, o agente pode convergit para comportamentos inesperados, necessitando reiniciar o treinamento todo.
- agente aprende por overfitting: difícil realizar transferência do que é aprendido para outro ambiente ou para uma pequena mudança no mesmo ambiente
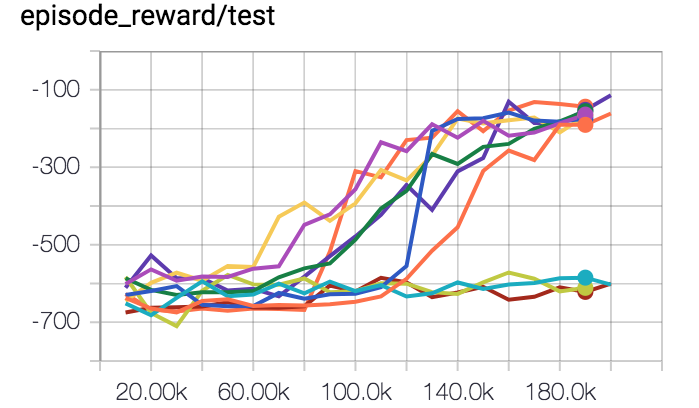
- sensibilidade a inícios aleatórios: o gráfico abaixo é um exemplo de treinar um algoritmo de DRL a equilibrar o pêndulo invertido várias vezes. Só funcionou 70% das vezes.
Algumas características de problemas nos quais aplicar DRL pode ser produtivo:
- é fácil gerar experiência em quantidades ilimitadas: quanto mais dados melhor, usar um simulador rápido
- é possível trabalhar num problema simplificado: ao invés de trabalhar no problema mais complexo possível (afinal, RL resolve tudo!), é melhor simplificá-lo e ver se o método resolve esse problema simplificado. E.g., trabalhar apenas em um cenário de muitos, com apenas um tipo de agente e espaço de ações limitado
- é possível utilizar self-play: em um cenário competitivo, permitir que o agente controle ambos os agentes e aprenda de si próprio. Funciona bem no AlphaZero, Dota 2 e Super Smash Bros.
- é fácil definir uma recompensa da qual o agente não possa se aproveitar: +1 por ganhar, -1 por perder. Nos papers de NAS, a recompensa é a acurácia da rede gerada no dataset de validação, ou seja, exatamente o que se deseja maximizar.
-
se a recompensa for modelada (reward shaping), tentar fazê-la ser rica: no ambiente que eu trabalhei durante o doutorado (SMAC), os agentes recebiam:
- uma recompensa proporcional à quantia de dano que inferiam no adversário, num determinado ataque
- uma recompensa maior por derrotar uma unidade adversária (last hit)
- uma recompensa maior ainda por derrotar todas as unidades adversárias (ganhar a partida)
o autor também aponta que, quanto menor o intervalo entre uma ação e a recompensa associada àquela ação, mais fácil para o agente aprender.
Enjoy Reading This Article?
Here are some more articles you might like to read next: