What's The Longest Word You Can Write With Seven-Segment Displays?
![]()
In this iPython notebook, I try to implement what was done in this video. Basically, we try to find out what are the longest words that can be displayed in a seven-segment display.
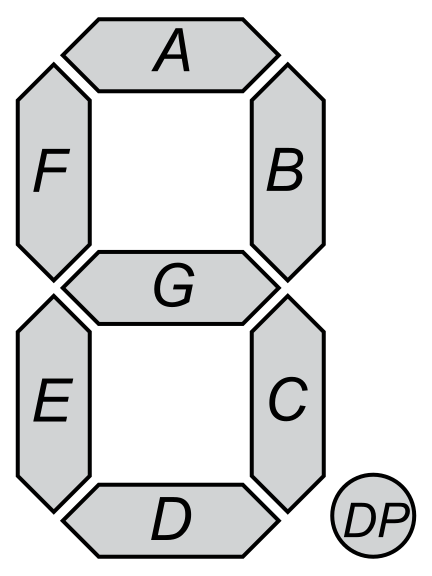
First, I download the same dictionary file that was used in the video.
import os
dict_file= 'words_alpha.txt'
if not os.path.exists(dict_file):
import urllib.request
url = 'https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt'
print('Downloading dictionary...')
urllib.request.urlretrieve(url, './'+dict_file)
import codecs
print('Fixing UTF-8 encoding issues before starting...')
f = codecs.open(dict_file, encoding='utf-8', errors='ignore')
data = set()
for line in f:
data.add(line)
print('Overwriting file with UTF-8 compliant content...')
target = open(dict_file, 'w')
target.write(''.join(data))
print('Done')
Then, I use the code that was also provided in the repository (which isn’t remarkable in any way, but I like to add the disclaimer that I did not code the following cell) to load all words into a set.
with open('words_alpha.txt') as word_file:
valid_words = set(word_file.read().split())
len(valid_words)
370098
Next, I use the same list of invalid letters that was used in the video. These are letters that can’t be displayed in a seven-segment display.
I use the set subtraction operation to remove invalid words from our giant set of words
invalid_letters='gkmqvwxz'
invalid_words = set()
for word in valid_words:
if any(elem in word for elem in invalid_letters):
invalid_words.add(word)
valid_words -= invalid_words
I then transform our giant set of words into a giant list of words and sort it by the size of the words in descending order.
valid_words = list(valid_words)
valid_words.sort(key=lambda x: len(x),reverse=True)
valid_words[0:30]
['dichlorodiphenyltrichloroethane',
'tetraiodophenolphthalein',
'scientificophilosophical',
'pseudointernationalistic',
'polytetrafluoroethylene',
'transubstantiationalist',
'pseudophilanthropically',
'phenolsulphonephthalein',
'chlorotrifluoroethylene',
'historicocabbalistical',
'pseudoenthusiastically',
'counterclassifications',
'dicyclopentadienyliron',
'scleroticochorioiditis',
'dacryocystoblennorrhea',
'hyperconscientiousness',
'pseudoaristocratically',
'cholecystenterorrhaphy',
'ultranationalistically',
'philosophicohistorical',
'psychotherapeutically',
'representationalistic',
'pseudophilanthropical',
'hyperpolysyllabically',
'dehydrocorticosterone',
'scientificohistorical',
'trichloroacetaldehyde',
'hyperenthusiastically',
'ureteropyelonephritis',
'disproportionableness']
Just to be thorough, I add the extra two letters that were added at the end of the video and filter the list again.
invalid_words = set()
for word in valid_words:
if any(elem in word for elem in 'io'):
invalid_words.add(word)
valid_words = list(set(valid_words) - invalid_words)
len(valid_words)
33352
valid_words = list(valid_words)
valid_words.sort(key=lambda x: len(x),reverse=True)
valid_words[0:30]
['supertranscendentness',
'superrespectableness',
'supersuperabundantly',
'unapprehendableness',
'supertranscendently',
'supersuperabundance',
'phenylacetaldehyde',
'understandableness',
'supersuperabundant',
'unsupernaturalness',
'subtransparentness',
'hyperbrachycephaly',
'untranscendentally',
'superadaptableness',
'ultrabrachycephaly',
'untranslatableness',
'pentadecahydrated',
'superaccurateness',
'unpersuadableness',
'unpresentableness',
'leadenheartedness',
'unattractableness',
'unprecedentedness',
'hyperbrachycephal',
'hyperaccurateness',
'characterlessness',
'unsurpassableness',
'supertranscendent',
'blunderheadedness',
'unadulteratedness']
Enjoy Reading This Article?
Here are some more articles you might like to read next: