I am going to run all experiments locally, using a 7th gen i7, an NVIDIA GTX 1070 and 32 GBs of RAM.
A lot of the heavy lifting will be done by the LangChain package, which I am on the process of learning to use.
On the road to building this Q&A bot, we will be introduced to many concepts:
- Document loading
- Text data cleaning using regex
- Splitting of Markdown documents into text chunks
- Sentence embeddings
- Vector stores
- Similarity search using cosine similarity between embedding vectors
- maximal marginal relevance search
- Self-query retrieval
- Contextual compression retrieval
- Question-answering with retrieval augmented generation
- Question-answering with retrieval augmented generation and custom templates
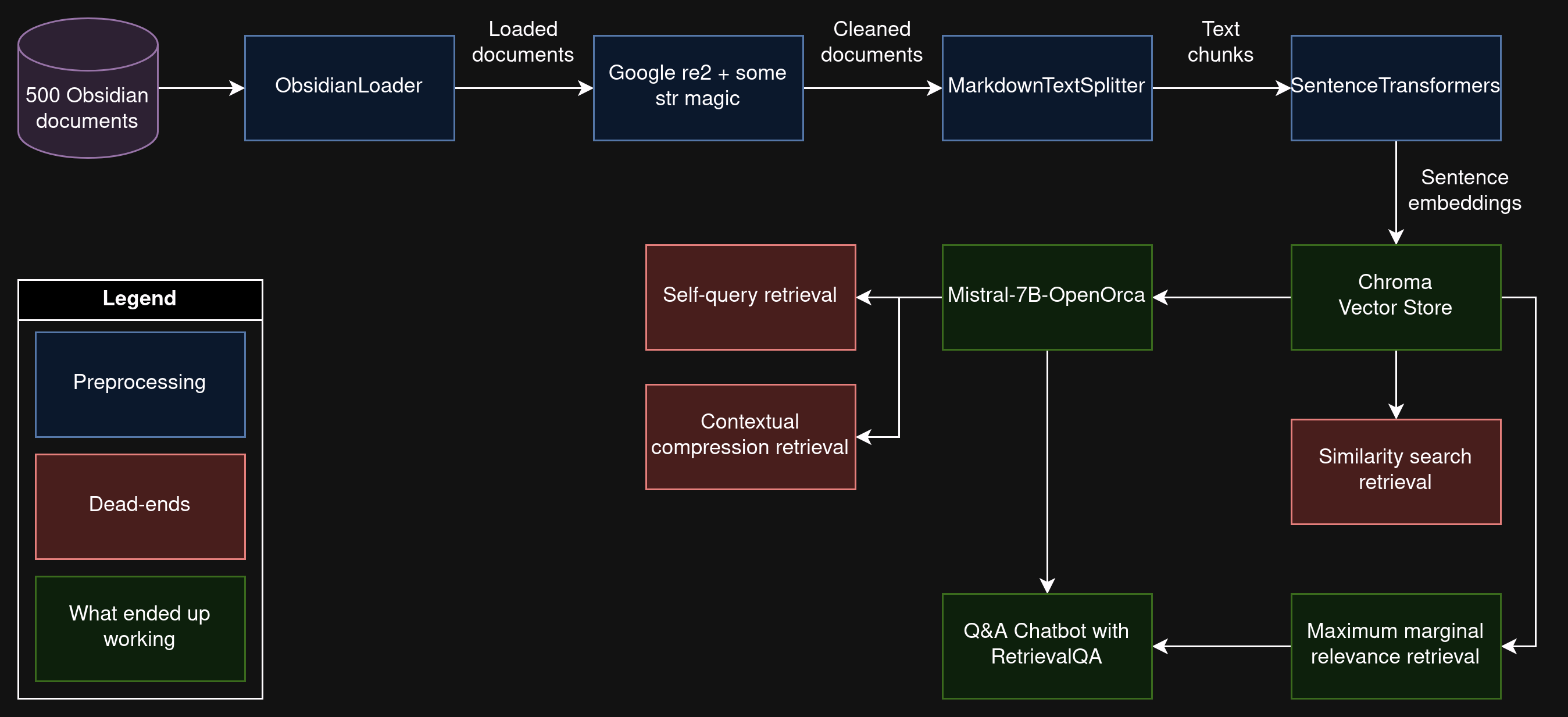
So that no one gets lost, the following diagram explains how the whole pipeline to get to our final Q&A bot (and how this notebook) works:
Prerequisites
- You can find the environment.yml file to create a conda env with the necessary dependencies to run the notebook.
-
You should download a model from the GPT4All website and save it on
./models/my_little_llm.gguf. The one below is the one I used.wget https://gpt4all.io/models/gguf/mistral-7b-openorca.Q4_0.gguf -O models/my_little_llm.gguf
Loading documents
Here I used the ObsidianLoader document loader and point it to the directory that contains all my notes in Markdown format.
We can see I have ~500 text files.
from pathlib import Path
docs_path = (Path.home() / "Documents" / "Obsidian").absolute()
from langchain_community.document_loaders import ObsidianLoader
loader = ObsidianLoader(docs_path, collect_metadata=True, encoding="UTF-8")
docs = loader.load()
print(f"Loaded {len(docs)} docs")
Encountered non-yaml frontmatter
Loaded 499 docs
Let’s take a peek at one of the documents. We can see it has the textual content itself, as well as some metadata. The ObsidianLoader includes file properties from Obsidian documents, such as tags, dates and aliases, as part of the metadata.
docs[7]
Document(page_content='A method for pre-training [[language model]]s in which the model has access to the first tokens of the sequence and its task is to predict the next token.\n\nThe following examples depict how a single sequence can be turned into multiple training examples:\n\n1. `<START>` → `the`\n1. `<START> the` → `teacher`\n1. `<START> the teacher` → `teaches`\n1. `<START> the teacher teaches` → `the`\n1. `<START> the teacher teaches the` → `student`\n1. `<START> the teacher teaches the student` → `<END>`\n\nModels trained using this method have access to the full sequence of tokens at inference time, making them appropriate for non-generative tasks that revolve around processing a sequence of tokens as a whole, for example:\n\n- [[Sentiment Analysis]]\n- [[Named entity recognition]]\n- [[Word classification]]\n\n[[Bidirectional Encoder Representation from Transformers|BERT]] is an example of a masked language model. Example from [[Bidirectional Encoder Representation from Transformers|BERT]]: Choose 15% of the tokens at random: mask them 80% of the time, replace them with a random token 10% of the time, or keep as is 10% of the time.\n\n## Sources\n\n- [[DeepLearning.AI Natural Language Processing Specialization]]\n- [[Generative AI with Large Language Models]]', metadata={'source': 'Causal language modeling.md', 'path': '/home/dodo/Documents/Obsidian/Causal language modeling.md', 'created': 1700448369.2719378, 'last_modified': 1700448369.2719378, 'last_accessed': 1708267659.2105181, 'tags': 'area/ai/nlp/llm', 'date': '2023-11-19 23:41'})
Cleaning documents
Obsidian documents have some of their own Markdown flavor, like [[Graph Neural Network|GNNs]], where Graph Neural Network is the name of a document and GNNs is what appears on the text. In cases like these, we want to keep only the second part.
It also has full-on links, such as [[grid world]], in which case we want to remove the double brackets.
# !pip install google-re2
import re2
docus = []
insane_pattern = r"\[\[([^\]]*?)\|([^\[]*?)\]\]"
for doc in docs:
s = re2.search(insane_pattern, doc.page_content)
if s is not None:
new_doc = re2.sub(insane_pattern, r"\2", doc.page_content)
docus.append(
(
doc.page_content,
new_doc,
)
)
doc.page_content = new_doc
doc.page_content = doc.page_content.replace("[[", "").replace("]]", "")
sorted(docus, key=lambda x: len(x[1]))[0]
('- [[Intersection over Union|IoU]]', '- IoU')
Splitting documents
This step splits the documents loaded in the previous step into smaller chunks.
LangChain provides its own Markdown text splitter, which we are going to use.
from langchain.text_splitter import MarkdownTextSplitter
splitter = MarkdownTextSplitter(chunk_size=400, chunk_overlap=50)
splits = splitter.split_documents(docs)
len(splits)
1510
Let’s take a peek at a chunk. They inherit the metadata of their parent document.
splits[542]
Document(page_content='# epsilon-soft policies\n\nAn $\\epsilon$-soft policy is a stochastic policy that always assigns a non-zero $\\frac{\\epsilon}{|A|}$ probability to all actions. These policies always perform some exploration.\n\nThe uniform random policy is an $\\epsilon$-soft policy. The epsilon-greedy policy also is.', metadata={'source': 'epsilon-soft policies.md', 'path': '/home/dodo/Documents/Obsidian/epsilon-soft policies.md', 'created': 1680669506.8282943, 'last_modified': 1680669506.8282943, 'last_accessed': 1708267660.780534, 'tags': 'area/ai/rl project/rl-spec', 'aliases': 'epsilon-soft policy', 'date': '2021-05-24 18:32'})
Computing embeddings and saving them to a vector store
To quickly search for text chunks, it is useful to precompute an embedding vector for each chunk and store it for future use.
An embedding vector is a numerical vector that represents the text chunk. It allows us to compare chunks in the embedding space. Chunks with similar semantic meaning tend to have similar embedding vectors. This similarity can be computed using e.g. cosine similarity.
My choice for embedding generator was SentenceTransformers, provided by Hugging Face, which runs locally.
# !pip install sentence_transformers
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings()
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Computed embedding vectors can be stored in vector stores. The one we will use in this project is Chroma. It is free, runs locally and is perfect for our small document base.
# !pip install chromadb
from langchain.vectorstores import Chroma
persist_directory = "docs/chroma/"
!rm -rf ./docs/chroma # remove old database files if any
vectordb = Chroma.from_documents(
documents=splits, embedding=embedding, persist_directory=persist_directory
)
vectordb._collection.count()
1510
Retrieval
Retrieval is the act of retrieving text chunks from our vector store, given an input prompt.
Basic retrieval is performed by comparing the prompt embedding with those of the text chunks. More complex retrieval techniques involve calls to an LLM.
Basic retrieval
Let’s first test a retrieval technique based on similarity search in the vector store. Given a prompt, the procedure should return the most similar or relevant chunks in the vector database.
The question below will be used as a test for everything else below in the notebook. It is related to reinforcement learning, an area in which I have a few hundred documents written on Obsidian. You can find more about the question here to see if our retrieval methods actually nail the answer.
question = "What is the definition of the action value function?"
The first example of retrieval is similarity search, which will convert the prompt into an embedding vector and compute the cosine similarity between the prompt embedding and the embeddings of all chunks in the vector store, returning the k most similar chunks.
retrieved_docs = vectordb.similarity_search(question, k=8)
for doc in retrieved_docs:
print(doc.page_content, end="\n\n---\n\n")
The action-value function represents the expected return from a given state after taking a specific action and later following a specific policy.
$$q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_t|S_t=s,A_t=a]$$
where $G_t$ is the Expected sum of future rewards.
---
A value function maps states, or state-action pairs, to expected returns.
- State-value function
- Action-value function
---
The state-value function represents the expected return from a given state, possibly under a given policy.
$$v(s)=\mathbb{E}[G_t|S_t=s]$$
$$v_{\pi}(s)=\mathbb{E}_{\pi}[G_t|S_t=s]$$
where $G_t$ is the Expected sum of future rewards.
---
The same goes for the Action-value function.
$$\begin{align}
q_*(s,a) & = \sum_{s'}\sum_r p(s',r|s,a)[r + \gamma \sum_{a'} \pi_*(a'|s') q_*(s',a')] \\
& = \sum_{s'}\sum_r p(s',r|s,a)[r + \gamma \max_{a'} q_*(s',a')]
\end{align}$$
---
Let's say we have a policy $\pi_1$ that has a value function $v_{\pi_1}$. If we use $v_{\pi_1}$ to evaluate states but, instead of following $\pi_1$, we actually always select the actions that will take us to the future state $s'$ with highest $v_{\pi_1}(s')$, we will end up with a policy $\pi_2$ that is equal to or better than $\pi_1$.
---
$$\begin{align}
v_*(s) & = \sum_a \pi_*(a|s) & \sum_{s'}\sum_r p(s',r|s,a)[r + \gamma v_*(s')] \\
& = \max_a & \sum_{s'}\sum_r p(s',r|s,a)[r + \gamma v_*(s')]
\end{align}$$
where $\pi_*$ is the Optimal policy.
The same goes for the Action-value function.
---
It's a function that dictates the probability the state will find itself in an arbitrary state $s'$ and the agent will receive reward $r$, given the current state the environment finds itself in, $s$, and the action chosen by the agent in $s$, depicted as $a$. It is usually denoted as $p(s',r|s,a)$.
Some properties of this function:
---
Policy evaluation is the task of finding the state-value function $v_{\pi}$, given the policy $\pi$. ^1b9b46
---
Maximal marginal relevance search
Plain similarity search has a drawback. It tends to recover chunks which are very similar or even identical, diminishing the overall amount of information present in the retrieved chunks.
To solve this, LangChain provides a method called maximal marginal relevance search, which works by “[…] finding the examples with the embeddings that have the greatest cosine similarity with the inputs, and then iteratively adding them while penalizing them for closeness to already selected examples.” [source]
retrieved_docs = vectordb.max_marginal_relevance_search(question, k=8)
for doc in retrieved_docs:
print(doc.page_content, end="\n---\n")
The action-value function represents the expected return from a given state after taking a specific action and later following a specific policy.
$$q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_t|S_t=s,A_t=a]$$
where $G_t$ is the Expected sum of future rewards.
---
A value function maps states, or state-action pairs, to expected returns.
- State-value function
- Action-value function
---
A generalization of Sarsa which employs the n-step return for the action value function,
!n-step return#^205a30 ^68659e
This estimate is then used in the following update rule for the action-value of the state-action pair at time $t$.
$$Q_{t+n}(S_t, A_t) \doteq Q_{t+n-1}(S_t, A_t) + \alpha [G_{t:t+n} - \gamma^n Q_{t+n-1}(S_t, A_t)]$$ ^ca04db
---
- if the agent exploits without having a good estimate of the action-value function, it will most likely be locked in suboptimal behavior, not being able to gather information from unknown transitions which might bring it more return.
---
Some properties of this function:
It maps states and actions to states and rewards, so its cardinality is $$p:S \times R \times S \times A \to [0;1]$$
It is a probability, so the sum over all possible combinations of states and rewards must be one,
$$\sum_{s' \in S} \sum_{r \in R} p(s',r|s,a) = 1, \forall s \in S, a \in A(s)$$
---
# Factored value functions in cooperative multi-agent reinforcement learning
<iframe width="560" height="315" src="https://www.youtube.com/embed/W_9kcQmaWjo?start=684" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
VDN was the first one and the one I used in my Doctorate.
---
- Exploitation: select the greedy action with relation to the action-value function.
- Exploration: select a non-greedy action.
---
Given the following MDP:
!Pasted image 20210523192818.png
The Bellman equation allows the value function to be expressed and solved as a system of linear equations: ^c06dd9
!Bellman equation for the state-value function#^a65ad4
---
LLM-backed retrieval
Some retrieval techniques require an underlying language model to be performed. The LLM may be used to, e.g. summarize or make chunks more coherent before returning them.
Instantiating the LLM
The LLM I chose is Mistral-7B-OpenOrca, provided by GPT4All.
- Mistral 7B is the best free and open 7 billion parameter LLM. It is also small enough to run on my GPU.
- The OpenOrca dataset is a conversation dataset.
- According to Mistral’s product website, this model has an 8k context window, which we should consider when retrieving chunks for it to process.
# !pip install gpt4all
# !pip install lark
# !wget https://gpt4all.io/models/gguf/mistral-7b-openorca.Q4_0.gguf -O models/my_little_llm.gguf
# !wget https://gpt4all.io/models/gguf/nous-hermes-llama2-13b.Q4_0.gguf -O models/my_little_llm.gguf
from langchain_community.llms.gpt4all import GPT4All
llm = GPT4All(model="models/my_little_llm.gguf", device="gpu")
llama.cpp: using Vulkan on NVIDIA GeForce GTX 1070
Self-query retrieval
Self-query is a technique in which an LLM is specifically prompted to output a structured query. It also allows it to take document/chunk metadata into consideration, as long as we describe each attribute in the metadata with a textual description.
Under the hood, self-query performs some pretty convoluted modifications to the original prompt and I advise you look at the documentation to understand what’s going on. [Source]
As we have seen when inspecting our splits, we can see that our data includes metadata taken from the file properties of Obsidian documents. We will go ahead and described them as attributes for the self-query retriever.
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="source",
description="The name of the Markdown file that contained the chunk. If you ignore the .md extension, it is the name of the article the chunk came from.",
type="string",
),
AttributeInfo(
name="aliases",
description="Other names for the article the chunk came from, if any.",
type="string",
),
AttributeInfo(
name="tags",
description="A series of comma-separated tags that categorize the article the chunk came from. When a tags starts with 'area', it denotes a broad area of knowledge. When it starts with 'project', it describes a specific project with beginning and end.",
type="string",
),
AttributeInfo(
name="authors",
description="When the document summarizes a scientific paper, this attribute holds a comma-separated list of author names.",
type="string",
),
AttributeInfo(
name="year",
description="When the document summarizes a scientific paper, this attribute contains the year of the publication.",
type="integer",
),
]
document_content_description = "A collection of study notes in Markdown format written by a single author, mostly about artificial intelligence topics."
The self-query retriever can also be configured to use maximal marginal relevance search, as you can see in the base_retriever argument below.
from langchain.retrievers.self_query.base import SelfQueryRetriever
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectordb,
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
base_retriever=vectordb.as_retriever(search_type="mmr", k=8),
)
retriever.invoke(question)
[Document(page_content='!Pasted image 20231129031306.png', metadata={'created': 1708307272.9665868, 'date': '2023-11-29 01:34', 'last_accessed': 1708307272.9699202, 'last_modified': 1708307272.9665868, 'path': '/home/dodo/Documents/Obsidian/Single linkage.md', 'source': 'Single linkage.md', 'tags': 'area/ai/ml/clustering'}),
Document(page_content='!Pasted image 20230317051147.png', metadata={'created': 1680667926.0942817, 'date': '2023-03-17 04:33', 'last_accessed': 1708267663.323892, 'last_modified': 1680667926.0942817, 'path': '/home/dodo/Documents/Obsidian/Comparing feature vectors in NLP.md', 'source': 'Comparing feature vectors in NLP.md', 'tags': 'area/ai/nlp project/nlp-spec'}),
Document(page_content='!Pasted image 20230325081439.png', metadata={'created': 1679742881.9000912, 'last_accessed': 1708267661.4972079, 'last_modified': 1679742881.9000912, 'path': '/home/dodo/Documents/Obsidian/Text cleaning.md', 'source': 'Text cleaning.md'}),
Document(page_content='!_attachments/Pasted image 20210523185724.png', metadata={'created': 1680669713.8148472, 'date': '2023-04-05 01:41', 'last_accessed': 1708267662.710553, 'last_modified': 1680669713.8148472, 'path': '/home/dodo/Documents/Obsidian/Iterative policy evaluation.md', 'source': 'Iterative policy evaluation.md', 'tags': 'area/ai/rl project/rl-spec'})]
As we can see, without more informative metadata (or better preprocessing of the text documents), the retrieved chunks are not very useful. It only retrieved chunks related to figures.
Contextual compression retrieval
As a final test on retrieval, we will implement a “contextual compression retriever”.
From the LangChain documentation:
The Contextual Compression Retriever passes queries to the base retriever, takes the initial documents and passes them through the Document Compressor. The Document Compressor takes a list of documents and shortens it by reducing the contents of documents or dropping documents altogether.
In our case:
- The base retriever will be a maximal marginal similarity search.
- The compressor will be Mistral-7b-OpenOrca.
Our hope is that the small, irrelevant chunks returned by the self-query retriever will be dropped and more relevant chunks will be summarized and returned.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=vectordb.as_retriever(search_type="mmr")
)
compressed_docs = compression_retriever.get_relevant_documents(question)
compressed_docs
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
[Document(page_content='The action-value function represents the expected return from a given state after taking a specific action and later following a specific policy.', metadata={'created': 1680669936.852964, 'date': '2023-04-05 01:45', 'last_accessed': 1708267660.0105264, 'last_modified': 1680669936.852964, 'path': '/home/dodo/Documents/Obsidian/Action-value function.md', 'source': 'Action-value function.md', 'tags': 'area/ai/rl project/rl-spec'}),
Document(page_content='Action-value function', metadata={'created': 1680669672.8131003, 'date': '2023-04-05 01:41', 'last_accessed': 1708267659.7238567, 'last_modified': 1680669672.8131003, 'path': '/home/dodo/Documents/Obsidian/Value functions.md', 'source': 'Value functions.md', 'tags': 'area/ai/rl project/rl-spec'}),
Document(page_content='*NO_OUTPUT*\n\nThe definition of the action value function is not mentioned in this context.', metadata={'created': 1633628586.5949209, 'date': '2021-03-02 23:01', 'last_accessed': 1708267661.2005382, 'last_modified': 1632030179.7187316, 'path': '/home/dodo/Documents/Obsidian/Factored value functions in cooperative multi-agent reinforcement learning.md', 'source': 'Factored value functions in cooperative multi-agent reinforcement learning.md', 'tags': 'None'}),
Document(page_content='Action-Value Function Definition: Not mentioned in the context.', metadata={'created': 1680669515.4254303, 'date': '2023-04-05 01:38', 'last_accessed': 1708267661.453874, 'last_modified': 1680669515.4254303, 'path': '/home/dodo/Documents/Obsidian/Exploration-exploitation tradeoff.md', 'source': 'Exploration-exploitation tradeoff.md', 'tags': 'area/ai/rl project/rl-spec'})]
These results seem much better than the previous ones, but they are still just a collection of chunks. When interacting with LLMs and chatbots in general, we expect a more direct response.
Question-answering using LLMs and RAG
In this example, we will perform retrieval augmented generation for question-answering in an Obsidian document database.
To summarize what we already have for this step:
- Our documents have been loaded and preprocessed.
- Chunks have been split from the documents, embedded and stored in the vector store.
- An LLM has been successfully loaded into memory.
Plain retrieval Q&A
This method of Q&A uses the prompt to find relevant chunks in the vector store. These chunks are called the context of the prompt and they are concatenated to the prompt, which is then passed directly to the LLM.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm, retriever=vectordb.as_retriever(search_type="mmr")
)
We can see which arguments the chain expects by inspecting the input_keys list.
qa_chain.input_keys
['query']
result = qa_chain({"query": question})
/home/dodo/.anaconda3/envs/langsidian/lib/python3.12/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function `__call__` was deprecated in LangChain 0.1.0 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
The result of prompting the overall system can be seen below. If you remember the definition of the action-value function [source], our Q&A bot has pretty much nailed it!
result
{'query': 'What is the definition of the action value function?',
'result': ' The action-value function represents the expected return from a given state after taking a specific action and later following a specific policy.'}
Under the hood, the RetrievalQA object uses a prompt template into which it replaces the context and the question before sending the full text prompt to the LLM. We can see it by inspecting the object’s graph.
qa_chain.get_graph().nodes
{'7eac904b44594e20852d8f0519ef0c3e': Node(id='7eac904b44594e20852d8f0519ef0c3e', data=<class 'pydantic.v1.main.ChainInput'>),
'8e824ec8c0654d0db3b83b56bd66b619': Node(id='8e824ec8c0654d0db3b83b56bd66b619', data=RetrievalQA(combine_documents_chain=StuffDocumentsChain(llm_chain=LLMChain(prompt=PromptTemplate(input_variables=['context', 'question'], template="Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n\n{context}\n\nQuestion: {question}\nHelpful Answer:"), llm=GPT4All(model='models/my_little_llm.gguf', device='gpu', client=<gpt4all.gpt4all.GPT4All object at 0x776da5594320>)), document_variable_name='context'), retriever=VectorStoreRetriever(tags=['Chroma', 'HuggingFaceEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x776cf1b45be0>, search_type='mmr'))),
'4b55a6602f9542fe8d583ac66c6ae722': Node(id='4b55a6602f9542fe8d583ac66c6ae722', data=<class 'pydantic.v1.main.ChainOutput'>)}
Retrieval Q&A with custom prompt template
The example below shows how to edit the prompt template used by the chain, albeit, in this case, with limited success. This is due to the limited performance of the LLM being used.
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. At the end of the response, say \"over and out\".
{context}
Question: {question}
Helpful Answer:"""
qa_chain_prompt = PromptTemplate.from_template(template)
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(search_type="mmr"),
return_source_documents=True,
chain_type_kwargs={"prompt": qa_chain_prompt},
)
Let’s ask a few questions to our Q&A bot and render the output as some nice Markdown.
Note that we can also output the documents that were retrieved during RAG and used to compose the answer, but that would pollute the output too much, so I left it commented out.
from IPython.display import Markdown
questions = [
"Given me the equation for the action value function update.",
"What is the overall architecture of the Deep Q-Networks?",
"What is the difference between causal language modelling and masked language modelling?",
"What is zero-shot learning?",
"Explain to me the concept of bucketing in RNNs.",
"What is a named entity in the concept of NLP?",
]
for q in questions:
result = qa_chain({"query": q})
display(Markdown(f"**Question: {result["query"]}**\n\n Answer: {result['result']}"))
# source_docs = "\n\n".join(d.page_content for d in result["source_documents"])
# print(
# f"Source documents\n\n{source_docs}"
# )
Question: Given me the equation for the action value function update.
Answer: The equation for the action-value function update is given by:
\[q_{\pi}(s,a) = R(s,a) + \<dummy32001>{ \gamma V_\pi (s') | s' \in S'}\]where $R(s,a)$ is the reward received when taking action a in state s and $\gamma$ is the discount factor.
Question: What is the overall architecture of the Deep Q-Networks?
Answer: The overall architecture of a Deep Q-Network (DQN) consists of an input layer, multiple hidden layers with nonlinear activation functions, and an output layer. It uses experience replay to store past experiences for training purposes, and employs target networks to stabilize the learning process. over and out
Question: What is the difference between causal language modelling and masked language modelling?
Answer: Causal language modeling refers to a method where the model predicts the next token in a sequence based on the previous tokens. In contrast, masked language modeling involves randomly masking some tokens during training time and then trains the model to reconstruct the original text by predicting the masked tokens.
Question: What is zero-shot learning?
Answer: Zero-shot learning refers to a model’s ability to perform new tasks without being explicitly trained on those specific tasks or examples. In the context of large language models, it means that an AI can execute new tasks without needing any explicit training data for those tasks.
Question: Explain to me the concept of bucketing in RNNs.
Answer: Bucketing in RNNs refers to grouping or organizing input sequences into fixed-sized groups, called “buckets”, before processing them with an RNN model. This technique helps improve training efficiency and reduce padding by ensuring that each bucket contains a sufficient amount of randomness and variability while preventing it from being too large so as not to introduce excessive padding.
Question: What is a named entity in the concept of NLP?
Answer: In the context of Natural Language Processing (NLP), a named entity refers to a real-world object that can be denoted with a proper name. Examples are a person, location, organization, product. It can be abstract or have a physical existence.
In some answers, the model has actually followed the instructions from the new prompt, but we need a much more powerful LLM, or the employment of techniques such as few-shot learning, to get better instruction-following results.
Conclusions
This notebook presented a proof-of-concept on how to create a question-answering bot powered by an LLM and with knowledge extracted from actual documents, more specifically, a collection of notes from Obsidian.
We were able to run all experiments locally, using a 7th gen i7, an NVIDIA GTX 1070 and 32 GBs of RAM.
We were also introduced to many concepts on the road to building this Q&A bot, such as:
- Document loading
- Text data cleaning using regex
- Splitting of Markdown documents into text chunks
- Sentence embeddings
- Vector stores
- Similarity search using cosine similarity between embedding vectors
- maximal marginal relevance search
- Self-query retrieval
- Contextual compression retrieval
- Question-answering with retrieval augmented generation
- Question-answering with retrieval augmented generation and custom templates
In future work, let’s build an actual chatbot that remembers previous answers and can keep up a lengthier conversation.
]]>